Day Two Automation Self Service Framework – Part 1
In my years on the administration and engineering side of the VMware world a task I was frequently responsible for was creating policies around the standards of my environment and then defining a process to ensure those policies were adhered to. Some examples of the policies I authored was things around snapshot lifetime, security hardening or datastore freespace, etc.
Often times these standards conflicted with the pressures I faced to complete requests in a timely fashion on the requests faced by my team and I. When faced with conflicting pressures like this you can chose to not enforce your established polices, which can have significant negative impacts when your team is audited or you suffer a negative impact to your environment as the result of not enforcing your established policies; or you can choose to not deliver the requested service in a timely fashion, which will likely have equally bad outcomes.
In this multi-part blog series we will explore one path mitigating the conflicting pressures by utilizing vROPS to monitor for violations of a given policy, and when detected performing automatic remediation of policy violations, while allowing a for exceptions. We will close with exploring how we can build upon this monitoring framework to deliver self-service capabilities of day two actions.
I’ll update the following list as I complete future entries in this series.
- Day Two Automation Self Service Framework – Part 1 (this post)
- Day Two Automation Self Service Framework – Part 2
- Day Two Automation Self Service Framework – Part 3
Today we review the example policy and the planned workflow we will use during this series. Let’s assume we have been tasked with enforcing the following policy
Virtual Machine snapshots are a way to provide a rollback point for potentially disruptive changes to the installed application(s) or operating system. They should not exist for longer than 72 hours. An exception may be granted to allow a snapshot to exist for 14 days.
Additionally, we will assume an “expectation” that service requests for snapshots are fulfilled within 2 hours of request.
The following diagram lays out the logical workflow we will be using to create this automated workflow to clean old snapshots and ensure we fulfill our SLA.
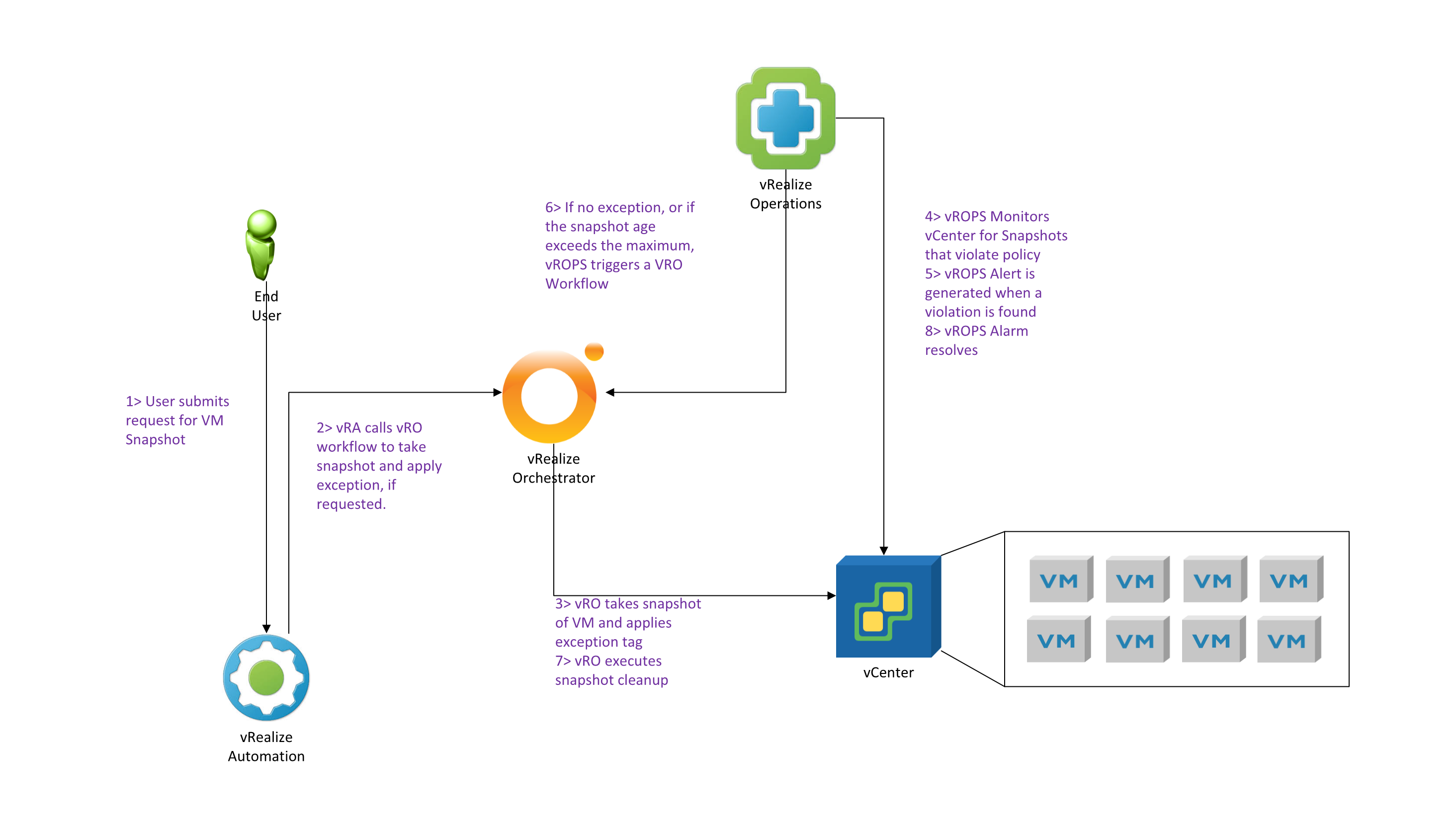
- The work flow starts with a end user requesting a vm snapshot for a specified virtual machine. This will be accomplished by creating a simple catalog item in vRealize Automation.
- When this catalog item is requested, vRA will pass the information received from the user to vRealize Orchestrator to initiate the process of taking a snapshot.
- A vRO workflow evaluates the parameters and determines if an exception for snapshot lifetime has been requested. If it has, it tags the virtual machine with an exception tag.
- vROPS performs monitoring of the environment, placing any machines with an exception tag in a specific monitoring policy that allows for longer snapshots.
- When vROPS discovers a snapshot exceeding 72 hours, an alert is generated.
- If the virtual machine associated to the alert does not have a snapshot lifetime exception tag, vROPS initiates a vRO workflow to remove the snapshot. If it has exception tag and is older then 14 days, it initiates a vRO workflow to remove the snapshot.
- vRO executes the snapshot cleanup
- The vROPS alert clears.
That’s it. Another easy button to allow you to drink more coffee while appearing more productive.
Future posts in this series will break down how to create this framework. We will start with the vROPS side of things, since it is a fairly simple and close to out of the box integration. From there we will cover the vRA self-service aspect.